Everything you need to know before picking your model — performance, price, speed, and real-world tradeoffs.
The Short Version
Anthropic dropped both models in early 2026, and the gap between them is smaller than you’d think — but real where it counts. Here’s the gist before we dig into the data.
✦ Sonnet 4.6 — Pick This If…
- Cost efficiency is a priority
- You’re running high-volume production workloads
- Computer use is central to your pipeline
- You need faster output and lower latency
- Everyday coding, agents, and office tasks
- Financial analysis (it actually beats Opus here)
✦ Opus 4.6 — Pick This If…
- You need absolute frontier reasoning depth
- Cybersecurity, life sciences, or hard research
- Multi-agent coordination at scale
- Hard knowledge tasks where errors are expensive
- Long-context retrieval across 1M+ tokens
- Novel problem-solving (ARC-AGI-2: 68.8% vs 58.3%)
Side-by-Side at a Glance
Same family, different league. Here’s how they stack up on the fundamentals before we dig into benchmarks.
| Metric | Sonnet 4.6 | Opus 4.6 |
|---|---|---|
| Release Date | February 17, 2026 | February 5, 2026 |
| API Model String | claude-sonnet-4-6 | claude-opus-4-6 |
| Input Pricing | $3 / 1M tokens Cheaper | $5 / 1M tokens |
| Output Pricing | $15 / 1M tokens Cheaper | $25 / 1M tokens |
| Context Window (Standard) | 200k tokens | 200k tokens |
| Context Window (Beta) | 1M tokens | 1M tokens |
| Max Output Tokens | — | 128k tokens Larger |
| Extended / Adaptive Thinking | Both supported | Both supported |
| Context Compaction (Beta) | Yes | Yes |
| Intelligence Index (Artificial Analysis) | 51 | 53 Higher |
| Output Speed (tokens/sec) | ~73 Faster | ~72 |
| End-to-End Response (500 tokens) | ~27.6s Faster | ~36.3s |
| Default for Free & Pro Plans | Yes | No |
Benchmark Breakdown
Numbers don’t lie — but context matters. Let’s walk through the key evals, task by task.
Full Benchmark Comparison Table
The complete picture — straight from the official Anthropic release data. Pink highlights in the original indicate the leader per eval.
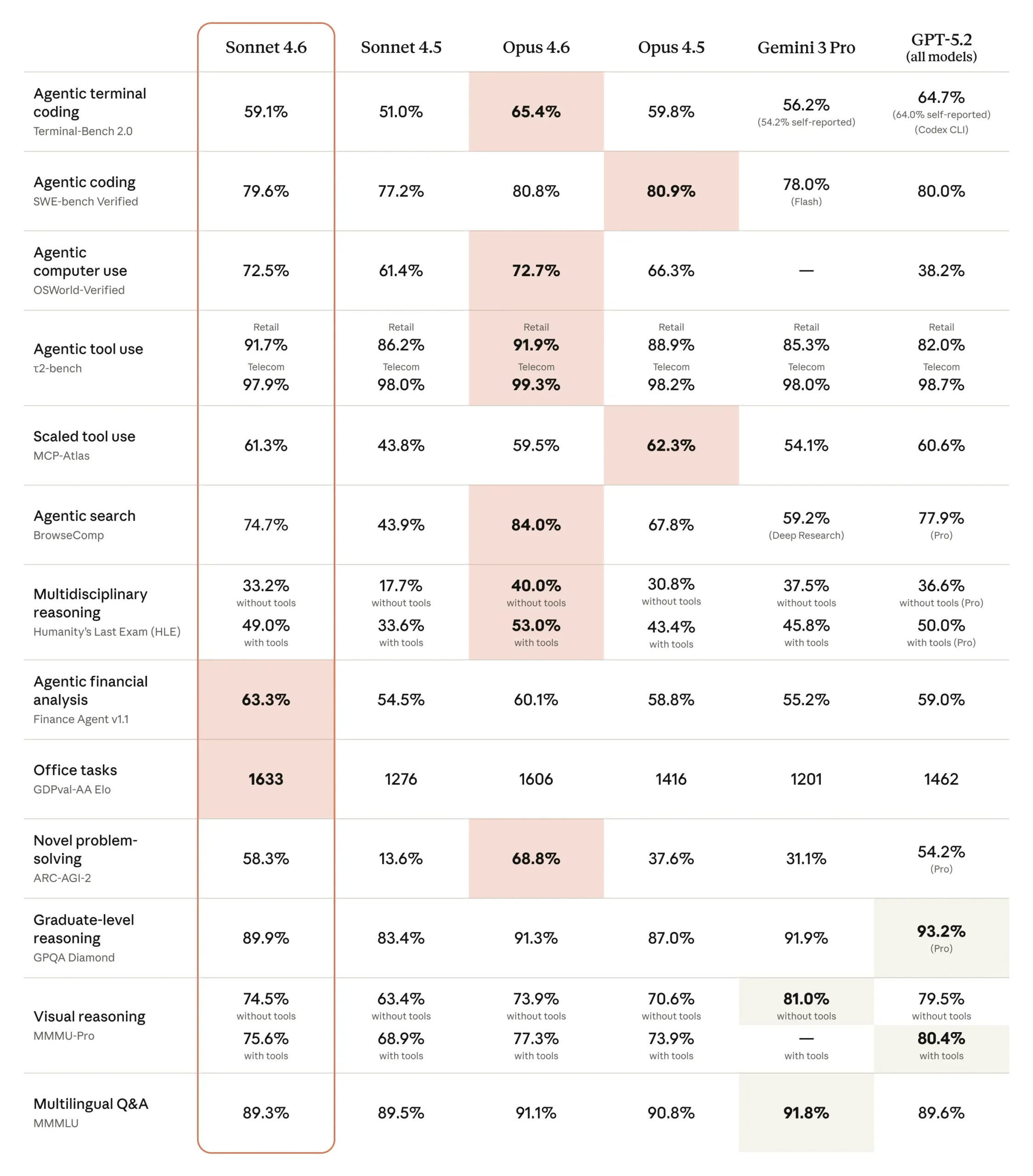
Winners, Eval by Eval
| Benchmark | Sonnet 4.6 | Opus 4.6 |
|---|---|---|
| Terminal-Bench 2.0 | 59.1% | 65.4% Winner |
| SWE-bench Verified | 79.6% | 80.8% Winner |
| OSWorld-Verified (Computer Use) | 72.5% | 72.7% ~Tie |
| τ²-bench Retail | 91.7% | 91.9% Winner |
| τ²-bench Telecom | 97.9% | 99.3% Winner |
| BrowseComp (Agentic Search) | 74.7% | 84.0% Winner |
| HLE with Tools | 49.0% | 53.0% Winner |
| Finance Agent v1.1 | 63.3% Winner | 60.1% |
| GDPval-AA Elo (Office Tasks) | 1633 Winner | 1606 |
| GPQA Diamond | 89.9% | 91.3% Winner |
| ARC-AGI-2 | 58.3% | 68.8% Winner |
| MMMU-Pro with tools | 75.6% | 77.3% Winner |
| MMMLU (Multilingual Q&A) | 89.3% | 91.1% Winner |
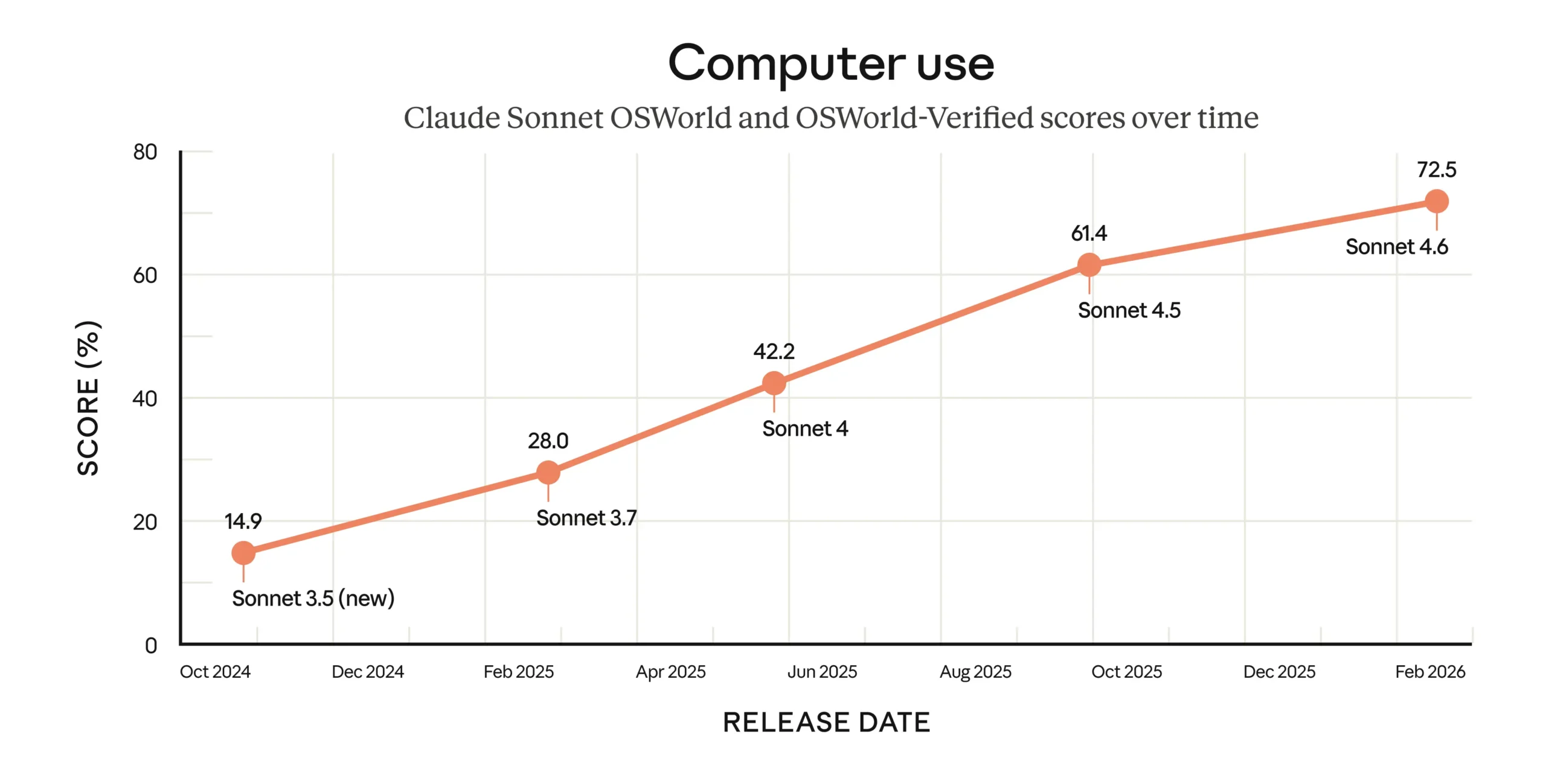
The Computer Use Story Belongs to Sonnet
One of Sonnet 4.6’s biggest talking points is OSWorld — 72.5%, up from Sonnet 4.5’s 61.4%. That’s a significant generational leap. And it’s only 0.2 points behind Opus 4.6 (72.7%), essentially a tie.
For context: when Anthropic launched general-purpose computer use in October 2024 with Sonnet 3.5, the OSWorld score was just 14.9%. In 16 months, that number nearly quintupled. The rate of progress here is the real story.
1M Context: Same Window, Different Execution
Both models offer a 1M token context window in beta (200k standard). But effectively using that context is where Opus 4.6 shows its edge.
On MRCR v2 at the 1M token scale — a needle-in-a-haystack test — Opus 4.6 scores 76%. Sonnet 4.5 scored just 18.5% on the same benchmark, showing how dramatically things have improved. On AA-LCR (Long Context Reasoning), they’re tied at 71% — so reasoning after retrieval is comparable. The difference is in retrieval fidelity at extreme lengths.
If your pipeline depends on finding buried details across truly massive documents, Opus 4.6 is the safer bet.
Sonnet 4.6 Can Run a (Simulated) Business
Vending-Bench Arena is one of the more creative evals out there: different AI models compete to run a simulated business and generate the highest profit over a year. Sonnet 4.6 developed a genuinely interesting emergent strategy — heavy early investment in capacity, then a sharp late-stage pivot to profitability.
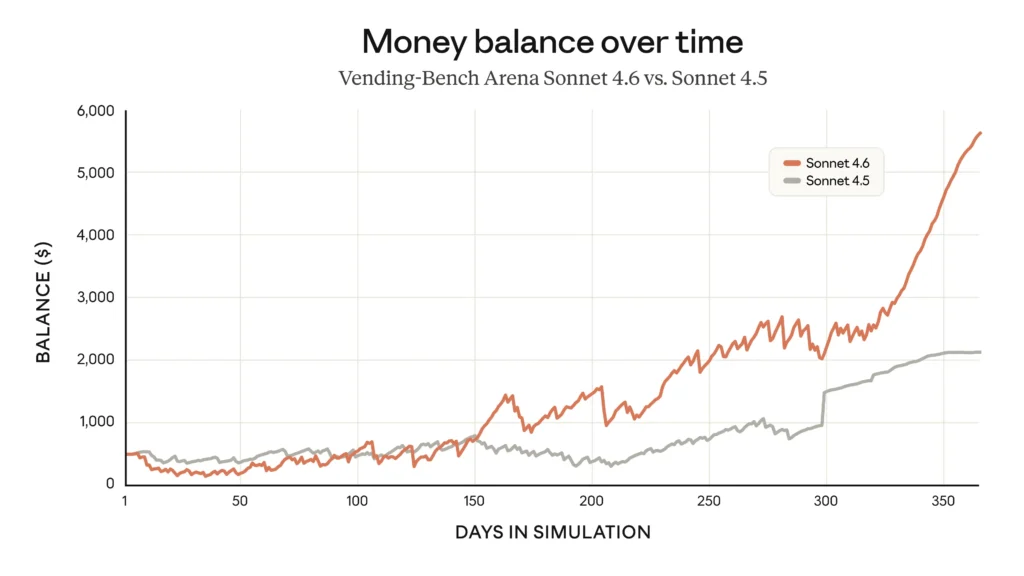
This particular matchup is Sonnet 4.6 vs Sonnet 4.5, but it demonstrates the kind of long-horizon planning previously associated with Opus-tier models. The capacity-investment strategy shows Sonnet 4.6 can reason about multi-stage tradeoffs in ways earlier models couldn’t sustain.
The Price-Performance Trade-Off
Opus 4.6 is objectively smarter on most raw benchmarks. But the cost delta is real — and at production scale, it compounds fast.
- ~73 tokens/sec output speed
- ~27.6s end-to-end for 500 tokens
- AI Intelligence Index: 51
- Default model for Free & Pro plans
- Top performer: computer use, finance
- ~72 tokens/sec output speed
- ~36.3s end-to-end for 500 tokens
- AI Intelligence Index: 53
- 128k max output tokens
- Leads on 10+ benchmark categories
Both Are Among the Safest Frontier Models Out There
Anthropic ran its most comprehensive safety evaluations to date for the Claude 4.6 generation — new tests for user wellbeing, updated refusal evals, and interpretability experiments. Both models performed well.
| Safety Dimension | Sonnet 4.6 | Opus 4.6 |
|---|---|---|
| Overall misaligned behavior rate | Low | Low (matches Opus 4.5) |
| Over-refusal rate | Low | Lowest of recent Claude models |
| Prompt injection resistance | Major improvement vs 4.5 | Similar to Sonnet 4.6 |
| Sycophancy / deception | Low | Low |
| Anthropic’s verdict | “Broadly warm, honest, prosocial, and at times funny” | “As aligned as Opus 4.5, our most-aligned model to date” |
The short version on safety: you’re not making a safety tradeoff when choosing between these two. The decision is purely about performance and cost.
Who Should Use What?
The data points to a clear answer for most use cases: Sonnet 4.6 is the right call the majority of the time. Opus 4.6 earns its premium on tasks where deeper reasoning actually changes the output quality — and where you can absorb the cost.
Developer building an AI product
Start with Sonnet 4.6. Handles most coding, tool use, and agent workflows at near-identical quality. Reach for Opus when your evals show drops on complex reasoning chains.
Enterprise at scale
Sonnet 4.6 by default. The ~40-67% cost reduction on output tokens is not trivial at volume. Reserve Opus calls for your hardest tasks and use a routing layer.
Research / deep analysis
Opus 4.6, full stop. Its lead on HLE, GPQA Diamond, and ARC-AGI-2 reflects genuine reasoning depth — the kind that shows up on hard, open-ended problems with no shortcut.
Computer use automation
Sonnet 4.6, easy call. The OSWorld gap (72.5% vs 72.7%) is negligible. You’re getting equivalent computer use capability at significantly lower cost.
Financial analysis / office tasks
Sonnet 4.6 actually wins here — 63.3% vs 60.1% on Finance Agent v1.1, and a higher GDPval-AA Elo (1633 vs 1606). Counterintuitive, but the data is clear.
Multi-agent orchestration
Opus 4.6. Stronger tool use (especially telecom: 99.3% vs 97.9%), 84% BrowseComp vs 74.7%, and better long-context retrieval make it the right anchor model for complex pipelines.